more on notion
-
Discovery
- singlestore form theo
- upstash KV, redis(no), couldflare kv?
- cold starts https://youtu.be/v-9AZKp-Ljo?t=197
-
Theory - 0
- Ways to connect
- Session pooler connetion string worked for me
- copying old proj string w diff password & port didn’t work
- Direct connection didn’t work
- supabase connections
-
direct connection
- Non-standard or default
- connection pooler
- what?
- there are a fixed number of connections open at any given time.
- When a user requests a connection, the pool provides an available one from its pool of connections.
- Once the user finishes with the connection, it’s returned to the pool, becoming available for reuse by other users
- why?
- it’s more perfomance heavy to open/close connections than to let maybe 4 open and never close them. Especially in scenarios where there’s a high frequency of requests
- how? - implemented through middleware
- tools - (postgres) - pgbouncer and pgpool-II
- what?
- APIs
- connection pooler
- Session pooler connetion string worked for me
- Security - you can mix them
- RLS - Raw Level - Row based on anything
- CLS - Column-level
- Object-level - db objects (tables, views, procedures etc)
- Role-Based - like discord servers
- ABAC - Attribute-based access control - more control w policies
- migrations
- Ways to connect
-
HT choose
- Sources
- K/V > Document > Relational
- Try to mentally start w K/V first then if you need more stuff just go with relational
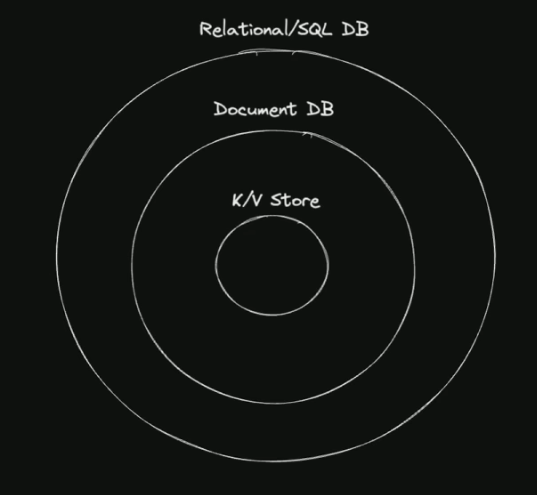
- don’t use
- bleeding edge stuff - do you want to risk on your data?
- mongo db
- without a clear motivation because you most likely need a relational DB because most data problems are relational
- firestore, ever
- Reliability
- never pick up bleeding edge without expecting anomalies
-
Main choices - sbt = suggested by theo
- My choices
- supabase - free plan
- railway - no free tier but 5$ scaling
- planetscale - no free tier, minimum 44$/m plan
- upstash - caching, integrates great w redis
- edge databases
- cockroach DB - sbt
- turso
- dynamo DB - managed NoSQL DB
- end game of cloud hosting
- On browser
- localstorage
- IndexedDB
- no
- firebase
- BSL license
- Redis
- mongoDB
- sources
- dsjim
- My choices
-
Types - src
-
Relational
- data integrity
- consistent
- accurate
- not damaged/lost
- ACID properties for transactions
- bad
- more complexity to scale horizontally
- data integrity
-
Key value
-
-
DB techs
- SQLite - minimal relational db
- originally meant offline but can be used online
- turso & libSQL made if “online” on the edge
- best thing is that it deploys anywhere
- is just a code library and a data file, you don’t need a server to deploy that db
- great for embedded solutions & apps that need a db
- when it is fine to store the data in a single file locally on the machine the program is running on but the data is structured and you want it to remain structured.
- more on use-cases -
- lightweight, less feature, cheap, faster than most DBs like mySQL
- mostly used in embedded systems
- reliable - less code
- Backward compatible and easily extendable.
- recorevable db content
- officially max 140 terabytes (depends on embedded system)
- originally meant offline but can be used online
- turso/libSQL - they made the latter - sqlite on the edge
- MySQL - Foss fast standard for medium to big stuff
- Stability Issues
- Poor performance on high loads (millions of records)
- no support for real-time data processing and analytics
- multi—threading
- Support embedded applications
- Postgre - Foss, less fast, better scaling, w more features
- Reliable - Highly stable & can handle a large data without crashing
- Flexibility - Supports a wide range of data types
- Complexity - configurable+, hard for new users to set up/maintain.
- Distributed & resilient DB
- What? DBs on the edge
- Servers on the edge are not enough, we also need the DBs to be closer to users… so let’s make 30 replicas distributed in the world
- foss
- CockroachDB
- built for Kubernetes
- Turso - uses sqLite
- CockroachDB
- What? DBs on the edge
- SQLite - minimal relational db

